



일도 바쁜데 AI 배워서 업무에 적용해 보자니, 유튜버들은 쉽다면서 막상 들어가 보니 공부 엄청 시키고, 업무에 응용하려면 너무 어렵죠?
구글 스프레드 시트 하나만 있어도 FGI(Focus Group Interview)를 통한 고객 인터뷰 데이터를 정리할 수 있는 방법! 그리고 더 나아가서 트렌드를 파악하기 위해 MAKE라는 툴을 활용하는 방법에 대해서 소개해 드리겠습니다! 이런 식으로 AI를 활용할 수 있다는 걸 보는 것만으로도 도움이 되실 거라고 생각하고, 또 이에 더해서 툴들을 직접 따라서 공부해 보시고, 현업에 적극적으로 활용하는 방법을 연구해 보시면, 굉장히 유용할 거라고 생각합니다!
HSAD에서도 지속적으로 애드레터를 발행하면서 트렌드를 파악하고 있는데요, 시장 트렌드를 조사하는 것은 하버드 비즈니스 리뷰(Harvard Business Review)에서도 소개한 바와 같이 중요한 일 중 하나이고 [1], 특히 생성형 AI를 활용할 수 있는 주요 예시 중 하나이기도 하죠!
인스타에서 글을 포스팅하고 나면 다른 사람들 글들은 슥슥 훑어보지만, 내가 올린 글은 댓글 하나하나 보고, 내가 관심 있는 다른 사람에 대해서는 유심히 들여다보는 것처럼, HSAD에서도 지속적으로 고객사가 관심을 가질 만한 고객사 관련 트렌드, 경쟁사나 관련 회사에 대한 정보를 파악하고 싶어 합니다. 하지만 매번 키워드를 바꿔가면서 정보를 찾는 건 여간 어려운 일이 아니죠!
‘매번!’이라는 말! 이는 곧 자동화를 할 수 있는 일이고, AI를 도입할 수 있는 지점을 가리키기도 합니다.
그럼 이제부터 저와 함께 구글 스프레드시트에서 GPT를 활용하는 방법과 이미 세계적으로 매우 유명한 Make라는 프로그램을 활용해서 업무 자동화를 하는 방법에 대해서 알아보아요! 보시는 분들이 불만을 표출하실 수도 있으니, 거짓말 안 하고 정말 쉽게 적용할 수 있는 부분만 알려드리겠습니다!?
구글 스프레드시트를 활용해서 고객 인터뷰(FGI) 데이터 정리하기
“고객 인터뷰 데이터를 엑셀파일로 15줄 정도, 감정은 긍정 부정 중립을 랜덤으로 만들어줘~ csv로 주면 더 좋고.”
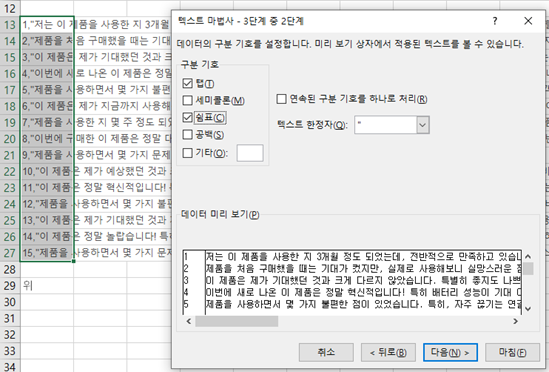
실제 데이터를 사용하는 대신 대형언어모델(Large Language Model, LLM)을 이용해 샘플 데이터를 받아보겠습니다. LLM 특성상 위의 제 예시와는 다른 데이터가 나올 거예요! 최근에는 ChatGPT, Claude, Grok, Gemini 등 너무 좋은 서비스들이 많이 나와서 LLM을 무료로 손쉽게 즐길 수 있게 되었습니다. 데이터를 처리하기 편한 파일 형식인 csv로 주는 경우도 있지만 그렇지 않은 LLM이라면 원본 데이터를 저처럼 위와 같이 엑셀 텍스트 마법사 활용해서 데이터를 분리해 주는 과정이 필요합니다!
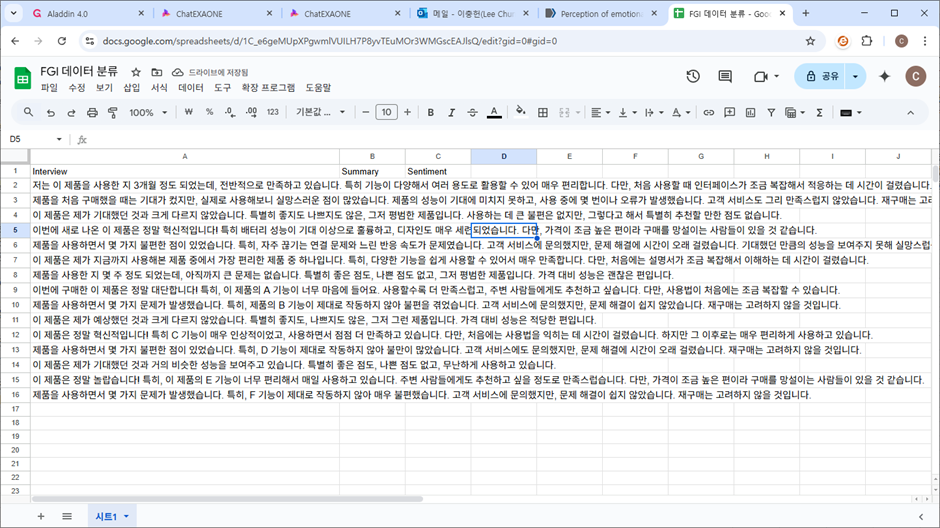
이제, 사람들의 인터뷰 데이터가 매우 길다고 가정하고 요약을 해보고 감정분석도 해봅시다! 구글 스프레드시트에 LLM 관련 몇몇 확장 프로그램이 있는데, 저는 그중에서 GPT Workspace라는 걸 쓰고 있어요. 설치를 하고 스프레드시트에서 열면 오른쪽과 같은 화면이 뜨는데요, 여러 기능들이 많이 있지만 제일 재미있다고 생각하는 기능은 바로 GPT 함수입니다! 더 자세한 설명은 참고자료 [2]를 봐주세요.

사용 방법은 말 그대로 위처럼 GPT를 엑셀 함수처럼 쓰는 겁니다! 저는 Summary와 Sentiment 아래 각각 아래와 같이 이렇게 써보겠습니다. 총 다섯 개의 변수를 GPT 함수 안에 쓸 수 있지만, 쉽게 사용할 수 있도록 앞의 두 개만 써보겠습니다. prompt는 “ ” 안에 넣어서 텍스트로 써주고 value는 해당 셀을 선택해 주시면 돼요. 그리고 원래 엑셀 작업을 하듯이 쭈욱 아래까지 긁어주면...?
=GPT("20자 이내로 요약해줘 감정이 잘 드러나게", A2)
=GPT("감정을 긍정,부정,중립 중 한 단어로 써줘", A2)
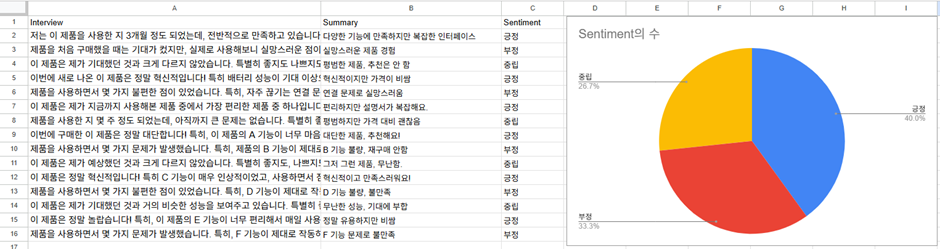

무려 이렇게 간단하게 긍정, 부정, 중립으로 데이터를 정리할 수 있습니다. 추가로 오른쪽에 보이시는 것처럼 시트의 기본 차트 기능까지 쓴다면… 이제 인터뷰 데이터를 그냥 원본 그대로 A 컬럼에 마구잡이로 넣어도 한 방에 요약과 감정분석, 시각화까지 이루어지는 것이죠..!
한 땀 한 땀 데이터를 보면서 요약하고 감정을 분석할 필요가 없어졌습니다! 이것도 원래는 베타 버전이어서 가격이 따로 있었는데 이제는 무료로 많이 사용할 수 있게 됐네요! 혹시 이 서비스가 사라진다고 하더라도 비슷한 여러 서비스가 있으니 대체해서 써 보시기를 권합니다.
Make 이용해서 뉴스 기사 수집(크롤링) 자동화하기
어때요? 여러 업무에 활용해 볼 생각에 설레시죠?
뭐라구요? 이런 데이터 자체를 불러오는 것까지도 어떻게 안 되냐구요? 욕심이 많으시군요! 그런 기능도 방금 하신 것처럼 GPT 함수를 통해서 어느 정도는 불러올 수 있습니다. 하지만, 기사 데이터 등 더 확실한 출처를 가지고 정보를 불러오고 싶다면 좀 부족할 수 있을 것 같아요. 그래서 오늘의 하이라이트 Make를 준비했습니다. Make는 세계적으로 가장 유명한 자동화 툴이에요. Adobe도 연동할 수 있고, 너무 많은 기능들이 들어가 있고, LLM을 적극적으로 활용할 수 있어서 매우 유용해요. 심지어 무료에다가 코딩도 하나도 안 해도 되는 완전한 노코드 소프트웨어입니다! 서비스가 중단될 가능성도 제로에 가깝죠!
하지만… 그럼에도 불구하고 처음 사용하는 사람들, 그리고 코딩에 익숙하지 않은 분들은 여전히 이런 것들을 익히기 어렵습니다! 그래서 제가 준비했습니다! 제가 드리는 json 파일을 import 해서 그대로 쓰시기만 해도 바로 사용이 가능합니다.
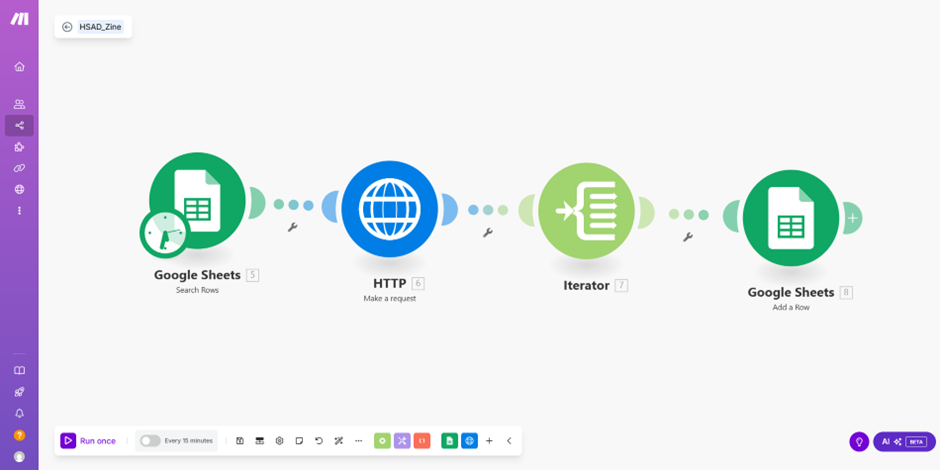
매우 중요한 개념만 말씀드리겠습니다! 우선 Make에 들어가서 “hsad_zine_chlee.json”이라는 제 파일을 Import blueprint라는 버튼을 눌러서 불러와주세요. 그럼 위와 같이 Make 내에 제가 미리 만들어 놓은 Scenario가 불러와질 거예요.
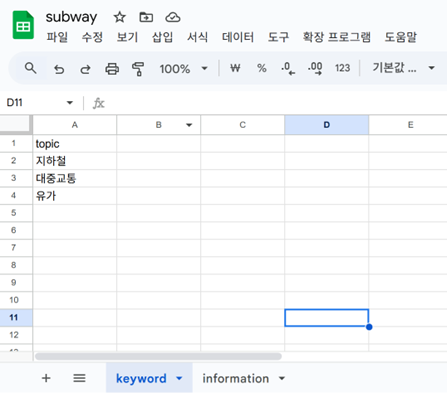
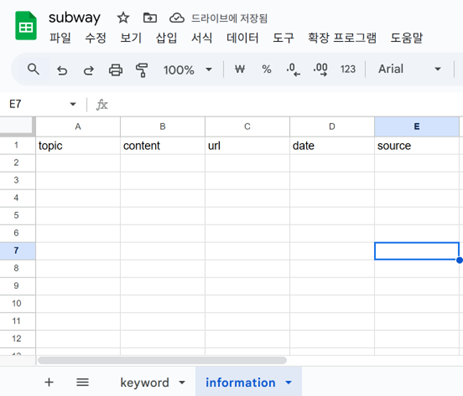
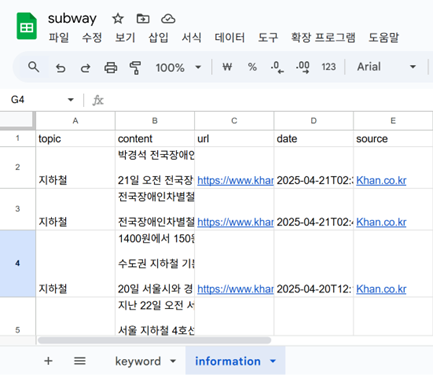
제가 만든 스프레드시트 링크 [3]을 참고해서 복제해도 좋고, 직접 해보고 싶다면 구글 스프레드시트에서 새로운 파일 subway를 만들고, 두 개의 시트를 위 스크린샷 내용과 완전히 동일하게 만들어주세요. 최근 LG 그룹의 계열사와 관련될 수 있는 흥미로운 혹은 논란이 될 수 있는 주제들이 많아서 쓰고 싶지만~ 논란의 소지가 없을 교통 관련 주제로 써보겠습니다~! 유가는 기름값을 의미합니다. 동음이의어가 많은 단어여서 이런 경우는 관련이 없는 주제의 뉴스는 제외하도록 할 수도 있겠지만, 복잡할 수 있으니 이 경우는 하지 않겠습니다.
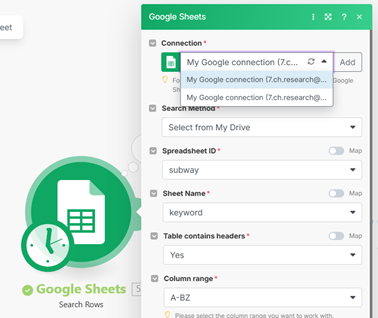
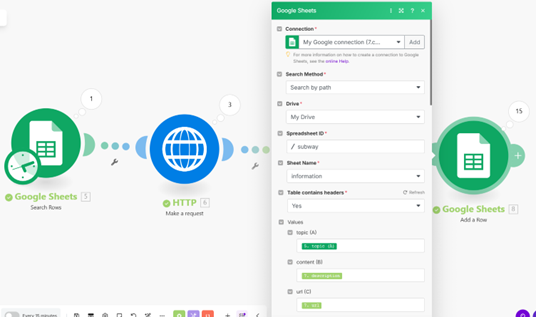
그런 뒤에는 구글 시트를 연동해 주시고, 위의 Connection에서 여러분의 구글 계정을 선택해 주세요. 아마 제가 쓴 것들 것 완전히 동일하게 잘 따라오셨다면 이제 더 이상 바꿀 내용은 없을 거예요. 다만 그 밑의 변수들은 클릭해서 그대로 선택해 주세요. 그리고 마지막에 있는 구글 스프레드 시트도 여러분의 시트로 연동해 주세요. 그러면…!
짠! 이렇게 차례대로 기사의 내용과 URL, 날짜, 출처가 다 불러와집니다! 네 번째 노드인 Google Sheets에서 불러올 항목을 다른 걸로 바꾸면 따른 여러 가지를 불러올 수도 있습니다! 원래는 이런 작업을 웹 크롤링이라고 해서 Python을 이용해서 나름 복잡하게 코드도 쓰고, html도 확인할 수 있어야 했던 복잡한 작업들이었는데, 이제는 정~말 쉬워졌습니다!
자 여기까지가 오늘 보여드리려고 했던 실습 내용의 끝입니다. 하지만 더 활용을 해보고 싶으신 분이라면, 이 글 처음에 GPT를 이용해서 스프레드시트 내용을 요약했던 것처럼 기사 내용을 요약하거나, 감정 분석을 하거나, 주요 키워드가 존재하는지 OX로 정리를 한다면… 그리고 Make 프로그램의 자동화 기능의 장점을 이용해서 이런 작업을 매일매일 특정 시간에 수행하도록 자동화를 해 둔다면 정말 좋겠죠?
사실 Make를 이용해서 ChatGPT (OpenAI) 기반의 요약이나 감정분석까지도 모두 수행할 수 있지만 그럼 너무 내용이 길어지고 복잡하니 이 정도로 해 두겠습니다. 혹시 더 많은 기능을 써보고 싶다면 제가 드리는 출처를 검색해서 공부해 보세요 [4, 5].
새로운 걸 공부하는 게 쉽지는 않겠지만, 하루 한두 시간만 머리 쥐어뜯으며 열심히 집중해 보시면, 일주일 만에 충분히 원하는 것들을 해낼 방법을 찾으실 거예요! 그럼 업무를 할 수 있는 범위가 무궁무진해지고, 효율도 엄청 좋아질 겁니다!






































{kind=link}
{kind=link}
{kind=link}
{kind=link}